Brainfuck is a minimalist programming language. It's mostly a toy and writing any real programs with it is almost impossible. Its design is very simple, the whole language has only eight valid instructions which operate on an array of bytes initialized to zero. Data on the array is manipulated through a pointer that points to the currently active cell.
| Character | Function |
|---|---|
| > | Increment pointer |
| < | Decrement pointer |
| + | Increment current memory location |
| - | Decrement current memory location |
| . | Output byte at current location |
| , | Read one byte and store it at the current location |
| [ | If byte at the current location is zero, jump to the matching ] |
| ] | If byte at the current location is not zero, jump to the matching [ |
A while ago I saw a brainfuck processor written for FPGA. It was quite inefficient because it was not pipelined and jump addresses were not stored anywhere, requiring checking all of the instructions between jumps. But it got me interested in writing a faster brainfuck microprocessor in VHDL. Below is a block diagram of the final design.
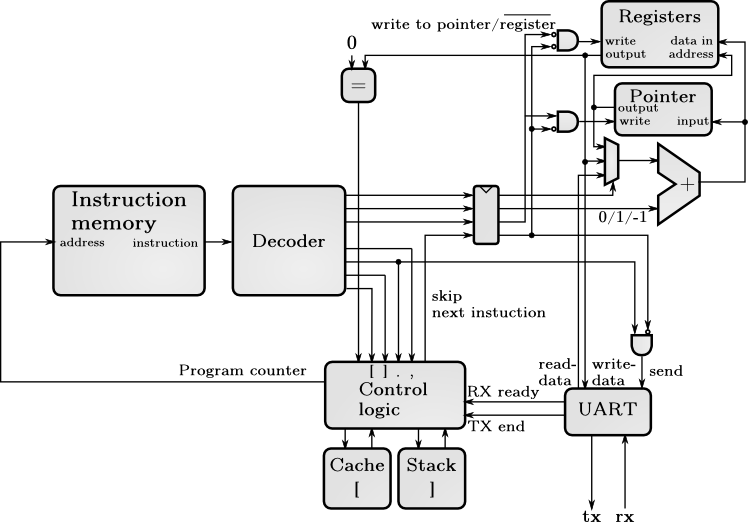
Block diagram of the final CPU
Operation
Executing instruction starts with fetching the instruction to execute from RAM. The read instruction is outputted to the decoder on the next clock cycle. Decoder will decode the instruction to signals that control the elements of the datapath. Control logic reads the decoder output signals and updates the program counter to fetch the correct instruction. On the third clock cycle decoder signals go to the datapath and the instruction is executed. Because the processor is pipelined, these three stages are done in parallel so there are always three different instructions executing.
Optimizations
]
Not so surprisingly, brainfuck isn't the best language to be executed on microprocessor for many reasons. Normally the jump instructions have destination encoded into them. This way the microprocessor can quickly load the next instruction. Brainfucks jump instructions, "[" and "]", jump to the matching bracket. This requires that we check all of the instructions until we find the matching bracket or have memorized where the matching bracket is.
Backwards jump is easy to memorize, because the program counter advances forward. If we find jump backward we should have gone over the matching bracket earlier, assuming of course that there are no unbalanced brackets. We can push the current program counter to stack on "[", and pop it on "]". This works well in practice, but I don't have any other implementations to compare its performance to.
[
If the current memory location is zero we jump forward on [ to the matching ]. This forward jump is harder than backwards jump, because we might not know where the matching bracket is if we haven't executed any code that far yet. So for the first time we have no choice but to advance one instruction at time until the matching bracket. When we have found the end of the jump we can store start and end addresses of the jump and on subsequent jumps we can read the stored address.
Cache associativity
I first had a one-way associative cache, where the location of stored entry would be indexed by lower bits of the program counter. This meant that when the cache had 16 entries every jump whose distance was a multiple of 16 would evict the existing jump from the cache. This didn't matter much in shorter programs, but it was a problem with Mandelbrot set program. Cache hit rate for forward jumps was 89.0%, so 11.0% jumps were evicted.
2-Way associative cache can have two entries with same index. This way there needs to be three jumps that are a multiple of 16 from each other to evict one of the entries. Cache keeps track of which entry was last used and replaces the least used entry. This gives a cache hit rate of 96.0% in Mandelbrot and ROT13 has 100.0% cache hit rate, not counting the first jumps that are compulsory misses.
Having the cache decreases the run time of ROT13 from 23059 cycles to 22632 cycles. Not that big improvement, but ROT13 is small program with small amount of jumps.
Mandelbrot takes 3 minutes and 55 seconds to execute with stack and without cache for forward jumps. With 8 entry 1-way cache runtime decreases to 3 minutes and 5 seconds. 8 entry 2-way cache has only slightly smaller run time of 3 minutes and 2 seconds. Doubling the cache size again decreases the run time by two seconds. Unfortunately this is the biggest cache possible. If I try to make it any bigger Xilinx's tools crash with unhelpful error "INTERNAL_ERROR:Xst:cmain.c:3464:1.56 - ".
Input and output
For ease of use I decided to have input and output through serial port. Mostly just because this allows reading and writing with computer, this makes checking the output much easier, which helps with the verification of the processor. Changing serial to parallel pins wouldn't take much work.
Possible optimizations
One brainfuck instruction doesn't do much work and it would be faster to combine some of the instructions to slightly more complex ones. For example because addition takes a constant time it would make sense to combine consecutive "+" or "-" to instruction that adds or substracts more than one at a time. Similarly it's possible to combine consecutive "<" and ">" instructions to one instruction that adds or substract more than one at a time from the pointer register. Also one often used brainfuck idiom for setting register to zero is "[-]" ("[+]" also works). This can in the worst case take 255*3 = 765 clock cycles and it would make sense to replace it with an instruction that zeroes the current register saving in the best case 764 clock cycles.
These optimizations would significantly increase the performance of the processor. However I have already used way too much time on this project and I don't have enough motivation left.
Results
The final design runs at 72MHz on my Papilio One 500K FPGA. The critical path changes slightly depending on how the Xilinx's tools synthetise it, but on fairly consistent path is pointer -> registers -> comparision to zero -> multiplexer in control block. Adding read and write pipeline stages would decrease this path, but I don't think the maximum clock frequency would rise that much, because control logic would start to limit it. Additional pipelining would also increase branch mispredict penalty from the current one clock cycle to three clock cycles. Simple branch prediction that predicts jumps backwards taken and forward jumps not taken achives correct prediction rate of almost 90%, so increased delay of mispredicted jumps would be probably worth it.
Amount of registers and size of cache and stack are in theory configurable, but due to padding the register pointer with zeroes, there needs to be at least 256 registers. Also if cache size is increased from 32 entries Xilinx's tools crash with internal error, so in reality the design isn't that configurable.
I tested the processor with three different programs:
Mandelbrot fractal by Erik Bosman (I'm seriusly impressed that this is possible)
Solution to 9 digit problem by Maya
All of the three programs run correctly. ROT13 and 9 digit solution both output answer in about second, but Mandelbrot set takes three minutes to calculate.
Source code is available at Github