Introduction

The same picture decoded with SDXL-VAE 0.9 (left) and 1.0 (right). Green and violet horizontal artifacts are visible near edges with the 1.0 VAE. Zoomed x8 from the original image.
Lately AI generated images have been getting so good that they are hard to distinguish from real photographs. Some of fake AI generated images have gone viral on social media with some users thinking they are real. Some notable examples are Pope wearing puffer jacket and Trump being arrested. There has been discussions on if AI generated content should be required to be clearly identified by law. Currently many of the big companies building these AI tools are trying to make sure that their tools are used responsibly by watermarking the outputs or limiting what the tools are able to do.
The new SDXL 1.0 text-to-image generation model was recently released that is a big improvement over the previous Stable Diffusion model. When the 1.0 version was released multiple people noticed that there were visible colorful artifacts in the generated images around the edges that were not there in the earlier 0.9 release limited to research use. The cause was determined to be VAE (Variational autoencoder) neural network that is responsible for encoding and decoding the input and output images to latent space that the diffusion u-net works with. The VAE encoder takes as input an RGB image and compresses it to latent space with 1/8 of original resolution with four channels. This smaller dimension makes the diffusion u-net more efficient. VAE also includes a decoder that takes the latent space representation and decodes it back to RGB image.
On social media there have been claims that the new artifacts generated by the 1.0 VAE are a watermark for detecting that images are AI generated but the Stability AI staff haven't commented on it. The Stability AI's official code and diffusers library include invisible watermark that is applied to the generated images to mark them as AI generated, this was also included in the earlier Stable Diffusion models. However, because the Stable Diffusion is open source and watermark is not a part of the neural net model and is applied afterwards to generated images it can be easily removed from the program. In fact, two of the most popular UI's A1111 and ComfyUI don't include this watermark and it is not present in the majority of the Stable diffusion images found in the wild.
Initially only SDXL model with the newer 1.0 VAE was available, but currently the version of the model with older 0.9 VAE can also be downloaded from the Stability AI's huggingface repository. The VAE is also available separately in its own repository with the 1.0 VAE available in the history.
SDXL 1.0 VAE changes from 0.9 version
Calculating difference between each weight in 0.9 and 1.0 VAEs shows that all the encoder weights are identical but there are differences in the decoder weights. It makes sense to only change the decoder when modifying an existing VAE since changing the encoder modifies the latent space representation that u-net works with which harms the quality of generated images.

Original image (left), reproduction error of 0.9 VAE (center) and 1.0 VAE (right). 256x256 original resolution.
Decoding 1024x1024 SDXL generated image resized to 256x256 image with both 0.9 and 1.0 VAEs and plotting the difference to the original image shows that in both cases the largest error is around the edges. With 1.0 VAE there is a clear stair case pattern around each edge. If you want you can view the images here: original, 0.9, 1.0.
{kind=link}
{kind=link}
{kind=link}
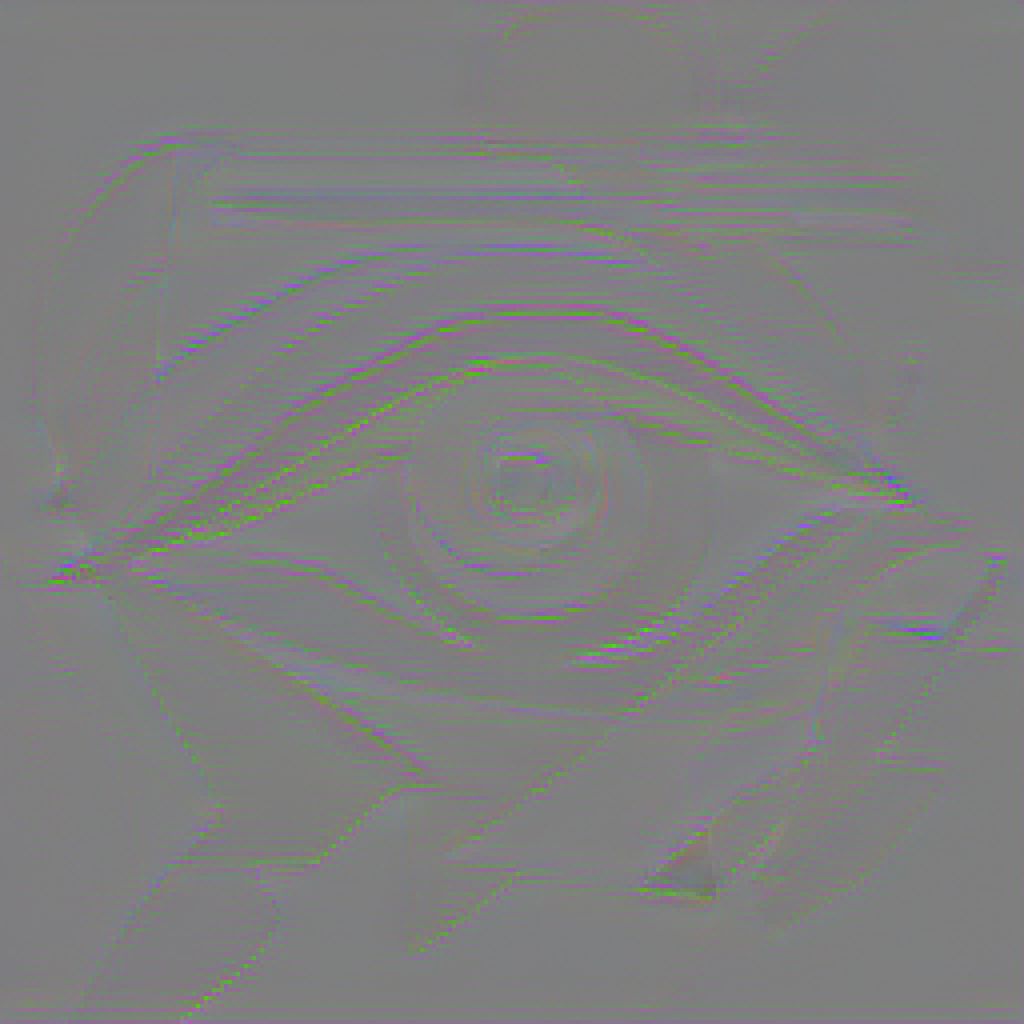
Difference of 1.0 encoded image to 0.9 encoded image. 256x256 original resolution.
This pattern is clearer when visualizing the difference between 0.9 and 1.0 VAE processed images. There is a clear green and violet pattern around every edge in the image.
PSNR measurement
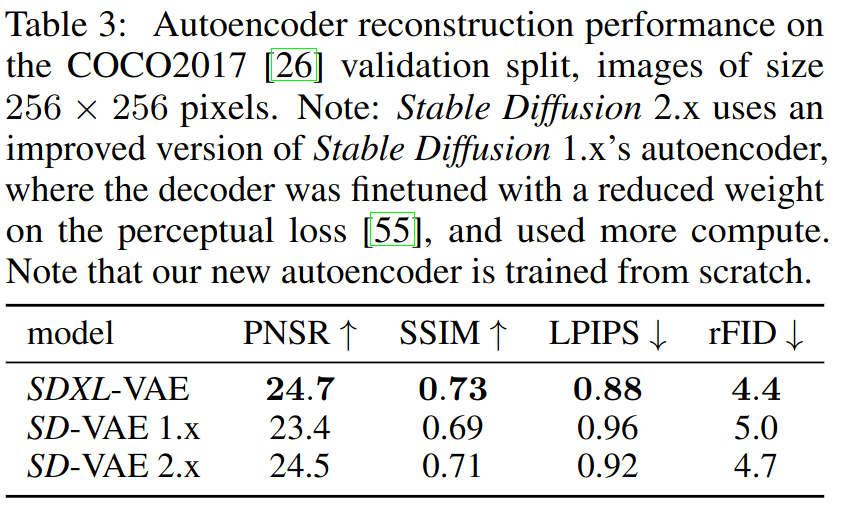
VAE measurements from SDXL report.
Stability AI published a report on SDXL that includes performance comparisons of VAEs in SDXL and older Stable Diffusion models on few different measures. Since there is a clear visual difference in SDXL 0.9 and 1.0 VAEs there should be also a difference in the objective measurements. PSNR is peak signal-to-noise ratio, it's SNR normalized to maximum signal dynamic range. I downloaded the COCO2017 validation dataset that was used in the report and ran the images through both VAEs and calculated the PSNR values on 256x256 resized images.
| VAE | PSNR (dB) |
|---|---|
| SDXL-VAE 0.9 | 25.74 |
| SDXL-VAE 1.0 | 25.37 |
The 0.9 VAE had higher (better) PSNR than the 1.0 VAE included with SDXL model. There is slight difference compared to the numbers presented in the SDXL report but I assume that is caused by how images are cropped and resized. The newer 1.0 VAE has about 0.4 dB lower PSNR. Stability AI trained a new VAE from scratch for SDXL to only slightly improve the performance compared to SD 2.X VAE. PSNR drop from 0.9 to 1.0 VAE is bigger than the gain in that training.
Identifying SDXL generated images from VAE artifacts
The 1.0 VAE artifacts are so visible that they can be spotted quite easily by just zooming in to the image and examining edges visually. However it's interesting to measure how easily the 1.0 VAE decoded images can be identified. Instead of looking manually at hundreds of images I decided to train a very simple neural network. Code is available at Github.
I first encoded and decoded COCO2017 training set images using 0.9 and 1.0 VAEs with 256x256 resolution and also saving the resized original 256x256 image. Then I trained a very simple neural net consisting of one convolution layer, global max pooling and two layer linear network. This is a very simple neural network and better performance could be obtained with a larger network. Especially the global max operation is problematic since only maximum of each convolution channel over the whole image is available for the linear layers.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
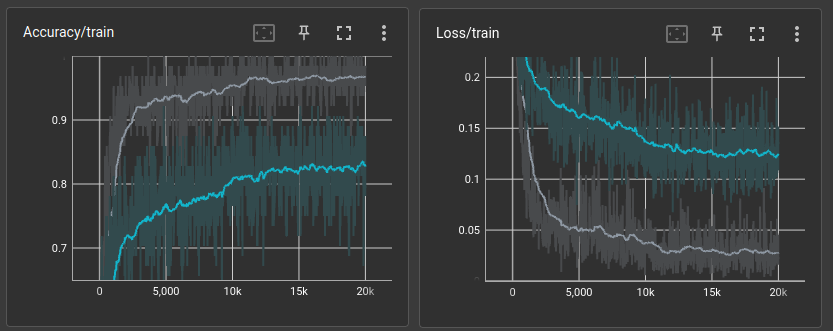
Training results. Grey curve is 1.0 VAE detector and blue 0.9 VAE. 1.0 VAE images are much easier to identify.
I trained the model two times trying to predict if image is decoded by 0.9 VAE and the same with 1.0 VAE. The training losses are shown above. The grey curve is trying to classify if the input image is generated by 1.0 VAE and blue the same for 0.9 VAE. Accuracy/train is the proportion of correctly classified samples in a batch and Loss/train is MSE loss. Training 20k steps with batch size of 64 took about 15 minutes on RTX 2080S GPU.
| VAE detector | COCO2017 validation accuracy |
|---|---|
| SDXL-VAE 0.9 | 82% |
| SDXL-VAE 1.0 | 96% |
Testing the detectors on COCO2017 validation set at 256x256 resolution shows that the 1.0 VAE encoded images are much easier to detect than 0.9 VAE encoded images 96% vs 82% accuracy. The detector trying to detect 0.9 VAE images also gets quite good accuracy of 82% which shows that even the 0.9 VAE without clearly visible artifacts does have some features in the output that allows the network to detect it. The detection ratio is based on simply rounding the output to zero or one.
A better detector should probably also try to detect the VAE artifacts after the image has been compressed with various image compression algorithms as most of the images on social media where it would be interesting to detect AI generated images are further compressed.
Visualizing the convolution kernels
Since the network is so simple it is much easier to analyze what it's doing compared to huge deep networks. To make visualizations even simpler I trained the network with just 8 convolution output channels instead of 64. The validation accuracy did drop to 90% for 1.0 VAE and 73% for 0.9 VAE indicating that the other 56 convolution kernels are beneficial but most of the work can be done with fewer kernels.

Detector input convolution kernels. 0.9 (left) and 1.0 (right).
The eight input convolution kernels are plotted above for 0.9 and 1.0 VAE detectors. They are quite different and it's clear that 1.0 VAE detector kernels on the right is trying to detect the green and violet horizontal artifacts.
Generalization to larger images

Example SDXL output image decoded with 1.0 VAE. Some artifacts are visible around the tracks when zoomed in.
The training and validation images were all from COCO2017 dataset at 256x256 resolution. These are quite different from typical SDXL images that have typical resolution of 1024x1024. I generated 200 images using SDXL with two different prompts for photorealistic and illustration images that were decoded with both VAEs. Detection threshold was set to 0.5, simply rounding the output to closer detection. The number of false positives and false negatives could be adjusted with different threshold parameter.
1.0 VAE detector identified 187/200 of 1.0 decoded images correctly as being decoded with 1.0 VAE and 198/200 of 0.9 decoded images correctly as not being decoded with 1.0 VAE.
0.9 VAE detector identified only 63/200 of 0.9 VAE decode images correctly. Since 1.0 and 0.9 VAE errors are similar apart from the 1.0 artifacts its not clear what it should report when tested on 1.0 decoded images but it identifies 158/200 of 1.0 decoded images as not being decoded with 0.9 VAE. The performance is much worse than 1.0 VAE detector and below 50% random guessing chance.
| VAE detector | LAION aesthetic subset accuracy |
|---|---|
| SDXL-VAE 0.9 | 41% |
| SDXL-VAE 1.0 | 94% |
On a portion of LAION Aesthetic dataset which consists of various images from the internet with different compression algorithms and parameters, the 1.0 VAE detector generalizes much better. In fact the 0.9 VAE detector gets less than 50% them correct that could be achieved with random guessing.
A slightly more complicated network with about the same number of parameters gets over 99% correct when detecting 1.0 VAE images.
It would be interesting to test if a better network trained with various compressed images would be able to detect artifacts from 0.9 VAE decoded images. 1.0 VAE decoded images are clearly easy to detect.
Conclusion
Detecting and marking of AI generated content is currently a hot issue. While Stability AI has not said if the SDXL outputs are watermarked on purpose, SDXL 1.0 neural net generates visible artifacts that makes it possible for generated images be identified with good accuracy with a simple neural network. However they can be identified also quite easily just by looking at them due to how easily visible the VAE artifacts are. The earlier SDXL 0.9 model does not have these same artifacts and identifying images generated by it is much harder.